I was a small part of a large Sandia project examining neuro-inspired hardware and algorithms (machine learning) as possible solutions for future non-traditional computer architectures. The project is called HAANA for Hardware Acceleratino of Adaptive Neural Algorithms. My interest is to help model how neural-network style algorithms perform on analog hardware, like resistive-memory crossbar arrays, which have the potential for very dense, low-power computing.
You can think of these crossbars as the ultimate processor-in-memory devices, where a current pulse passes through a resistor to perform a multiply/add in a matrix-vector multiply. The crossbar stores a matrix of weights; setting a resistor to a new value is the equivalent to settng the value of a single matrix element in a traditional numeric algorithm.
To simulate how crossbars perform on actual numeric maachine-learning algorithms, we created an open-source simulation tool called CrossSim which is available for download, and was used in several of the following papers.
This is a paper where we simulate crossbars built of analog resistive memory devices to model the effects of noise, non-linear responses, and device-to-device or cycle-to-cycle variabilities and see how they effect the effectiveness of an simple neural-net backpropagation algorithm:
Resistive Memory Device Requirements for a Neural Algorithm Accelerator, S. Agarwal, S. J. Plimpton, D. R. Hughart, A. H. Hsia, I. Richter, J. A. Cox, C. D. James, M. J. Marinella, IEEE International Joint Conf on Neural Networks (IJCNN 2016), Vancouver, Canada, Jul 2016. (abstract)
In this paper a novel idea by Sapan Agarwal is exploited to increase the accuracy of a machine learning algorithm running on noisy analog devices:
Achieving Ideal Accuracies in Analog Neuromorphic Computing Using Periodic Carry, S. Agarwal, R. B. Jacobs-Gedrim, A. H. Hsia, D. R. Hughart, E. J. Fuller, A. A. Talin, C. D. James, S. J. Plimpton, and M. J. Marinella, 2017 IEEE Symposium on VLSI Technology, Kyoto, Japan (2017). (abstract)
Here is a paper focused on a specific kind of resistive memory device, pioneered by Alec Talin at Sandia:
Li-Ion Synaptic Transistor for Low Power Analog Computing, E. J. Fuller, F. E. Gabaly, F. Léonard, S. Agarwal, S. J. Plimpton, R. B. Jacobs-Gedrim, C. D. James, M. J. Marinella, A. A. Talin, Advanced Materials, 29, 1604310 (2017). (abstract)
Here is a survey paper of the field:
A historical survey of algorithms and hardware architectures for neural-inspired and neuromorphic computing applications, C. D. James, J. B. Aimone, N. E. Miner, C. M. Vineyard, F. H. Rothganger, K. D. Carlson, S. A. Mulder, T. J. Draelos, A. Faust, M, J. Marinella, J. H. Naegle, S. J. Plimpton, Biologically Inspired Cognitive Architectures, 19, 49-64 (2017). (abstract)
Sandia has a cluster-computing effort to build and use a series of large-scale cluster supercomputers with off-thte-shelf commodity parts. Collectively these machines were called CPlant, which is meant to invoke images of a factory (producing computational cycles) and of a living/growing heterogeneous entity.
I'm just a CPlant user, so here are the salient features of the machine as compared to Tflops from an application point-of-view. These numbers and all the timing results below are for the "alaska" version of CPlant which has about 300 500-MHz DEC Alpha processors connected by Myrinet switches. A newer version "siberia" with more processors and a richer interconnect topology is just coming on-line (summer 2000).
| Intel Tflops | DEC CPlant | |
| Processor | Pentium (333 MHz) | Alpha (500 MHz) |
| Peak Flops | 333 Mflops | 1000 Mflops |
| MPI Latency | 15 us | 105 us |
| MPI Bandwidth | 310 Mbytes/sec | 55 Mbytes/sec |
In a nutshell the difference a cluster means for applications is faster single- processor performance and slower communication. As you'll see below, this has a negative impact on application scalability, particularly for fixed-size problems. Fixed-size speed-up is running the same size problem on varying numbers of processors. Scaled-size speed-up is running a problem which doubles in size when you double the number of processors. The former is a more stringent test of a machine's (and code's) scalability.
Below are scalability results for several of my parallel codes, run on both Tflops and CPlant. A paper with more details is listed below.
IMPORTANT NOTE: These timing results are mostly plotted as parallel efficiency which is scaled to 100% on a single processor for both machines. The raw speed of a CPlant processor is typically 2x or 3x faster than the Intel Pentium on Tflops. Thus on a given number of processors, the CPlant machine is often faster (in raw CPU time) than Tflops even if its efficiency is lower.
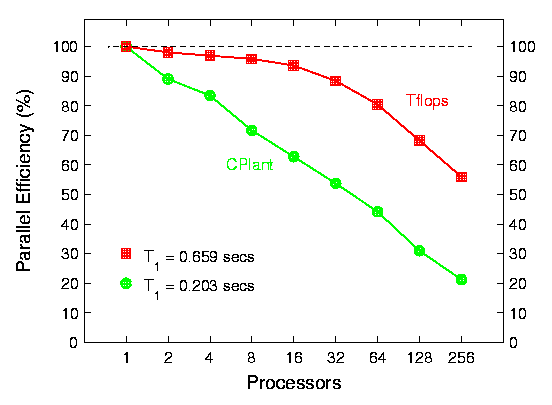
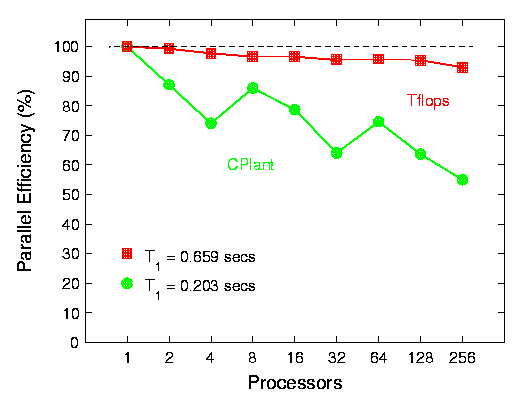
This data is for a molecular dynamics (MD) benchmark of a Lennard-Jones system of particles. A 3-d box of atoms is simulated at liquid density using a standard 2.5 sigma cutoff. The simulation box is partitioned across processors using a spatial-decomposition algorithm -- look here for more info on this benchmark.
The 1st plot is for a N = 32,000 atom system (fixed-size efficiency). The 2nd plot is scaled-size efficiency with 32,000 atoms/processor -- i.e. on one processor an N = 32,000 simulation was run while on 256 processors, 8.2 million atoms were simulated. In both cases, one processor timings (per MD timestep) are shown at the lower left of the plot.
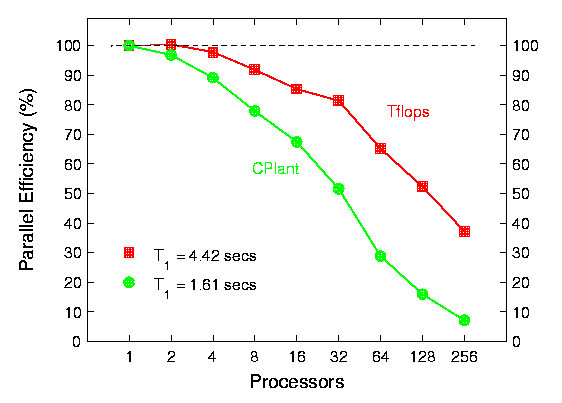
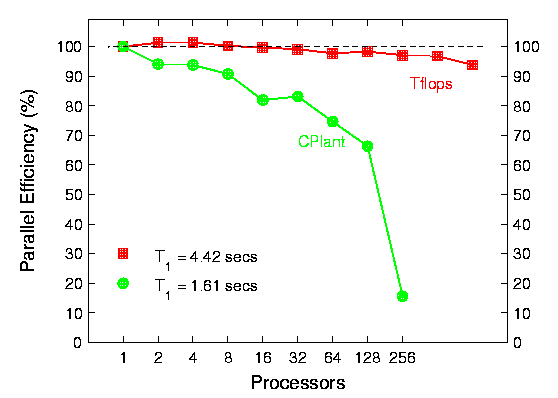
This data is for running a full-blown molecular dynamics simulation with the LAMMPS MD code of a lipid bilayer solvated by water. A 12 Angstrom cutoff was used for the van der Waals forces; long-range Coulombic forces were solved for using the particle-mesh Ewald method.
The 1st plot of fixed-size results is for a N = 7134 atom bilayer. The 2nd plot is scaled-size results for 7134 atoms/processor -- i.e. on one processor an N = 7134 simulation was run while on 1024 processors, 7.1 million atoms were simulated. Again, one processor timings for both machines (per MD timestep) are shown at the lower left of the plots. On the scaled-size problem, the CPlant machine does well until 256 processors when the parallel FFTs take a bit hit in parallel efficiency.
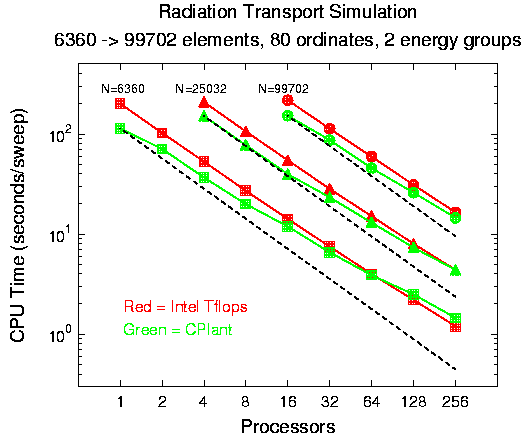
This performance data is for a radiation transport solver. A 3-d unstructured (finite element) hexahedral mesh is constructed, then partitioned across processors. A direct solution to the Bolztmann equation for radiation flux is formulated by sweeping across the grid in each of many ordinate directions simultaneously. The communication required during the solve involves many tiny messages being sent asynchronously to neighboring processors. Thus it is a good test of communication capabilities on CPlant.
Solutions were computed for three different grid sizes on varying numbers of processors. For each simulation 80 ordinate directions (Sn = 8) were computed using 2 energy groups. CPU times for 3 different grid sizes running on each machine are shown in the figure. The CPlant processors are about 2x faster, but the CPlant timings are not as efficient on large numbers of processors (dotted lines are perfect efficiency for CPlant).
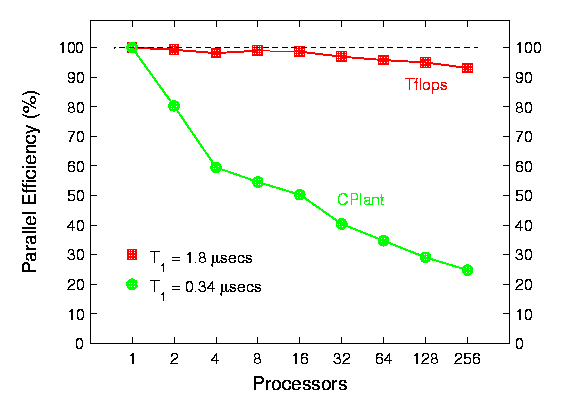
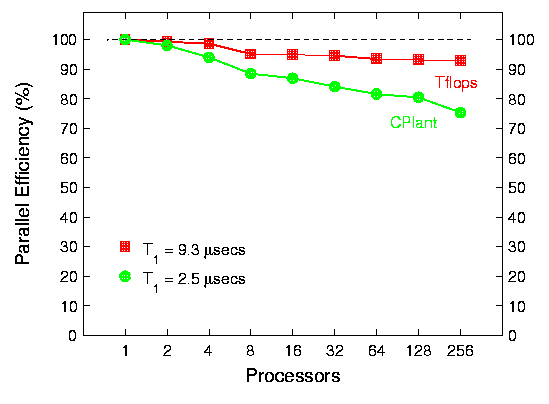
These plots are timing data for the QuickSilver electromagnetics code solving Maxwell's equations on a large 3-d structured grid that is partitioned across processors. The first plot is for a fields-only finite-difference solution to a pulsed wave form traveling across the grid. The efficiencies are for a scaled- size problem with 27,000 grid cells/processor. Thus on 256 processors, 6.9 million grid cells are used. The timings in the lower-left corner of the plot are one-processor CPU times for computing the field equations in a single grid- cell for a single timestep. Single-processor CPlant performance for the DEC Alpha is about 5x faster than the Tflop's Intel Pentium. The 2nd plot is for a QuickSilver problem with fields and particles. Again, scaled-size efficiencies are shown for a problem with 27,000 grid cells and 324,000 particles per processor. Thus on 256 processors, 83 million particles are being pushed across the grid at every timestep. The one processor timings are now CPU time per particle per timestep.
This paper has been accepted for a special issue of JPDC on cluster computing. It contains some of the application results shown above. It also has a concise description of CPlant, some low-level communication benchmarks, and results for several of the NAS benchmarks running on CPlant.
Scalability and Performance of a Two Large Linux Clusters, R. Brightwell and S. J. Plimpton, J of Parallel and Distributed Computing, 61, 1546-1569 (2001). (abstract)